 Ziva is a character in the TV show NCIS that speaks at least 9 languages. When a trademark is submitted to the USPTO, the translations for any non English words are submitted. Our Ziva is an attempt to infer from the rather messy metadata for translations a clean dictionary of words tranlated into many langugages. For example, the trademark submission for the beer Corona includes the translation notes that "Corona is the Spanish word for Crown".
Ziva is a character in the TV show NCIS that speaks at least 9 languages. When a trademark is submitted to the USPTO, the translations for any non English words are submitted. Our Ziva is an attempt to infer from the rather messy metadata for translations a clean dictionary of words tranlated into many langugages. For example, the trademark submission for the beer Corona includes the translation notes that "Corona is the Spanish word for Crown".
We take each translation and use it as a *fact* for building relationships:
1 TR0010,"The Spanish words ""Las Cruces"" mean ""The Crosses"".",72089117
2 TR0000,"THE WORD ""PARADISO"" IN ITALIAN MEANS ""PARADISE"".",72089445
3 TR0010,"The mark ""Caleche"" is a French word meaning ""A Four-Wheeled Carriage"".",72089649
These relationships are then ingested into a graph database (Neo4j) and queries can be made. The validity of the *translations* can be judged by the number of trademarks that submit that translation.
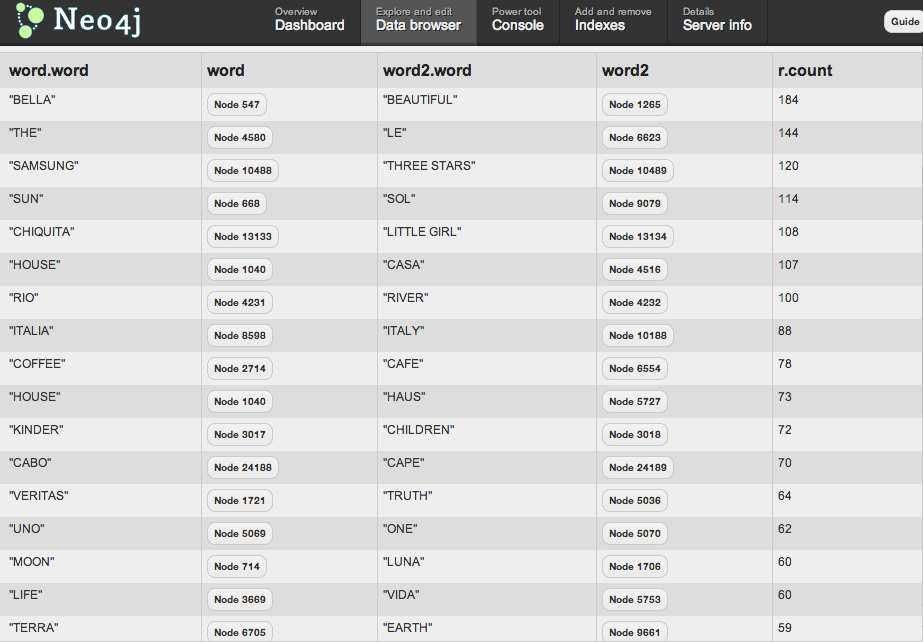
Here are the most commonly translated words in the trademark corpus. It's interesting to learn that the literal translation of SAMSUNG is "THREE STARS" in Korean!
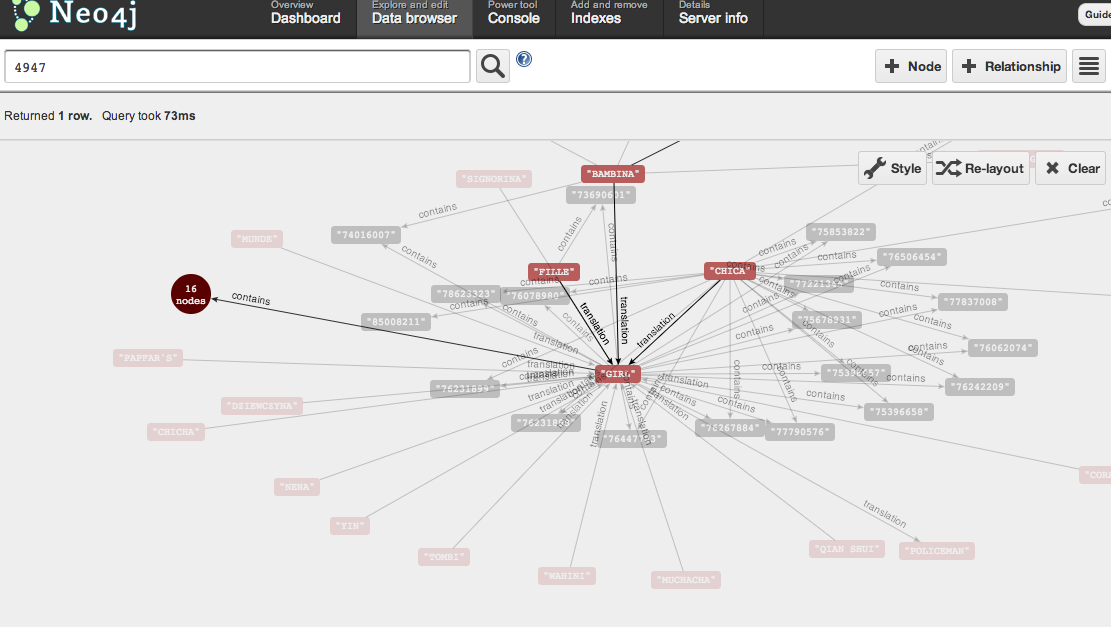
The word "GIRL" is a great example of this network effect:
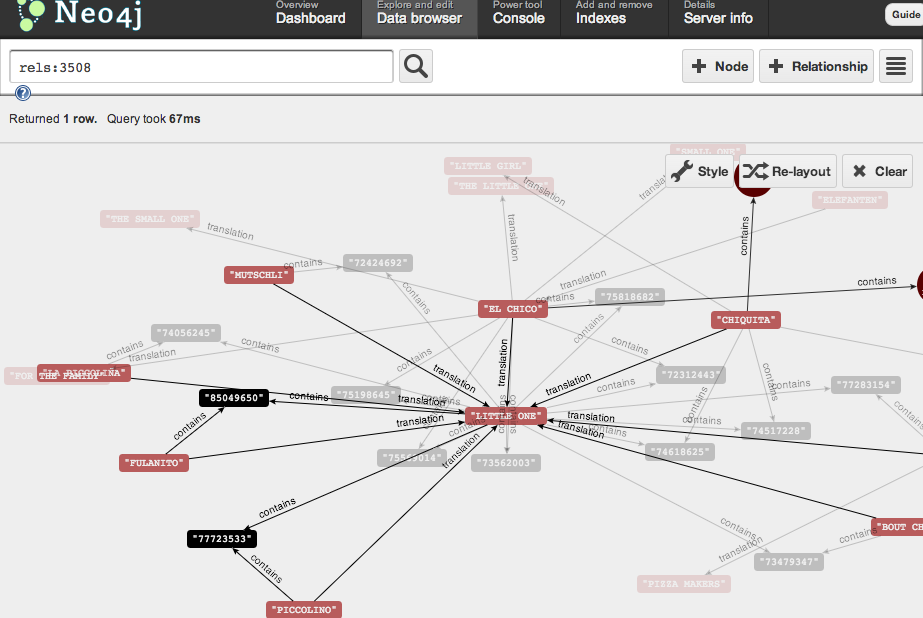
And if you click from "GIRL" to "CHIQUITA", you end up back in English at the node "LITTLE ONE". From that node, we can see a number of what I would call endearments in various language:
 In the future we would like to:
In the future we would like to:
- Go deeper in the parsing of the source file to produce “facts”. We only pull out the simplest pattenrns.
- Build a simple interface to crowd source validating the facts. Allow users to dispute a fact, and feed that data back into the graph.
- Allow the user interface to reflect the strength of connections by showing stronger connections in forefront, and weaker connections in the background.